

Sorting Of Documents Based On A Particular Field
In this blog we will perform sorting of a document based on a particular field, sample input and output documents are given below:
Input:

Output:

Overview of the use case:
- We will read the document mentioned in the input section using the Disk V2 connector.
- We will convert the document into a Flat file and use the Enforce Unique option in the Flat file profile to remove the duplicates(In case we have duplicates in our document).
- We will use one Groovy script to perform the sorting.
- Finally, we will convert the document back to JSON format.
Steps:
Step 1. Go to platform.boomi.com
Step 2. Login by giving your valid credentials (Username and Password).
Step 3. The home page will be displayed, now click on “Integration”.

Step 4. Click on the “Create New” button.

Step 5. Select “Process” and click on “Create”.

Step 6. Choose Start shape as “Connector” type and choose connector as “Disk V2”

Step 7. Click on ‘+’ icon in the Connection to configure the connection.

Step 8. Give the connection name as ‘Disk’, in the directory text field give the directory path from where you want to read the file, at last click ‘Save and Close’.

Step 9. Select action as “Get” and Click on “+” icon in Operation to configure operation.

Step 10. Give the operation name as “Read file” and click on “Save and Close”.

Step 11. Click on Parameter, then click on the “+“ button.

Step 12. Select Input as ID, give the file name(test.json) in static value and hit on “Ok”.

Step 13. Drag and drop a Map shape and click on “+” icon.

Step 14. Choose the JSON profile in the Source.

Step 15. Create one Flat file also for our input. Make sure the Enforce Unique check box should be checked in Name element.

Step 16. Map all the elements and click “Save and close”.

Step 17. Drag and drop a Data process shape and click on the “+” icon to add a processing step.

Step 18. Select Spil Documents, choose Profile Type as Flat file, Split option as Split By Line as shown below:

Step 19. Drag and drop a Set Properties shape and click on the “+” icon to add a property.

Step 20. Select property type as Dynamic Document Property and give the property name “SORT_BY_SEQUENCE” and click on “Ok”.

Step 21. Click on “+” icon to add Property value.

Step 22. Choose Type as Profile Element, choose the EMP FF profile and in Element choose the Sequence element. Click on “Ok”.

Step 23. It will look like this, now click on “Ok”

Step 24. Drag and drop one Data Process shape and click on the “+” icon to add a processing step.

Step 25. Choose Custom Scripting as Processing Step, Script Source is Inline Script and Language is Groovy 1.5. Now click on “Edit Script” to write the script.

Step 26. Write this scripting for performing sorting.
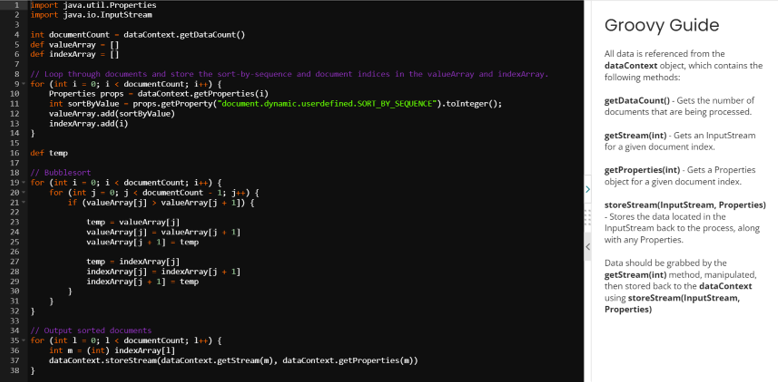
Note – Here is a small demonstration of the above scripting:
//import the necessary libraries.
import java.util.Properties
import java.io.InputStream
//Store the document count in documentCount.
int documentCount = dataContext.getDataCount()
//Create two arrays, one for storing the Sequence values and other one for storing the indexes for them.
def valueArray = []
def indexArray = []
// Loop through documents and store the sort-by-sequence and document indices in the valueArray and indexArray.
for (int i = 0; i < documentCount; i++) {
Properties props = dataContext.getProperties(i)
int sortByValue = props.getProperty(“document.dynamic.userdefined.SORT_BY_SEQUENCE”).toInteger();
valueArray.add(sortByValue)
indexArray.add(i)
}
// Performing Bubble sort using two for loops and using 3rd variable (temp).
def temp
for (int i = 0; i < documentCount; i++) {
for (int j = 0; j < documentCount – 1; j++) {
if (valueArray[j] > valueArray[j + 1]) {
temp = valueArray[j]
valueArray[j] = valueArray[j + 1]
valueArray[j + 1] = temp
temp = indexArray[j]
indexArray[j] = indexArray[j + 1]
indexArray[j + 1] = temp
}
}
}
// Output sorted documents back in the process.
for (int l = 0; l < documentCount; l++) {
int m = (int) indexArray[l]
dataContext.storeStream(dataContext.getStream(m), dataContext.getProperties(m))
}
Step 27. Click on “Ok”.
- As we split the document before, now we need to combine them again.
- We will add one more processing step in same Data Process shape.
Step 28. Click on “+” icon choose Processing Step as “Combine document”, Profile Type is “Flate File” and Headers Option is “Retain First Line as Column Header”, click on “Ok”.

Step 29. Drag and drop a Map shape. Click on “+” icon.

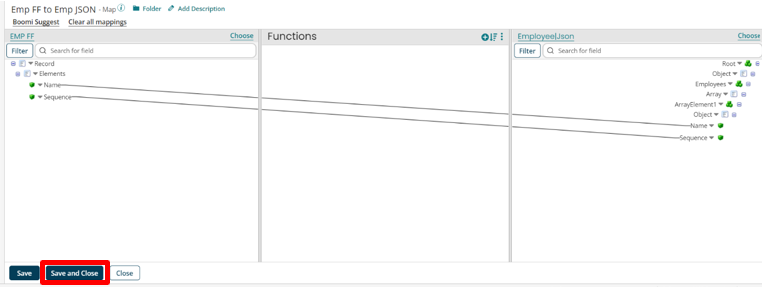
Step 30. In the place of Source choose the Emp Flat File profile which we have created previously and choose the Emp JSON profile in the Target.
Map all the fields. Click on “Save and Close”.
Step 31. Finally add a stop shape at the last.
It will look like this:

Step 32. Now test the process.

Step 33. Check the document from shape source data of first Map shape. And compare with the document in the shape source data of Stop shape.
